As an media scholar and journalist with an interest in the digital divide, I have long believed that one of the things that media outlets could do a lot better is using their higher profile to give a voice to ‘ordinary people’ who have something to say. I also believe that one of the things that Facebook like other news intermediaries should be trying to do is increase ideological diversity in their feeds. Lastly, I am aware that it is not right to judge what people say online just because it is poorly written technically. And then this happens.
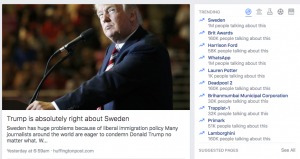
This is my top Facebook recommended story on Facebook’s top trending issue. The story’s summary suggests it is from the Huffington Post, which has some journalistic credibility, but if you visit the story itself and look carefully you will see that it is an un-edited, un-curated self published blog posting.
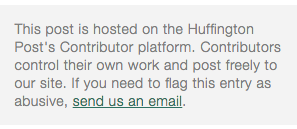
It is also badly written, bigoted, and dismayingly lacking in concrete, citable facts.
There was a riot of violence and destructions by immigrants in the capitol of Sweden, Stockholm. The police was forced to shoot with ammunition to put and end to it. In Malmö, another city south in Sweden they have struggle with gang violence and lawlessness for years. So when Trump talk about that Sweden have an immigration problem he [Trump] is actually spot on.
It’s well known for Scandinavians and other Europeans that liberal immigration comes with drugs, rapes, gang wars, robbery and violence
(For a more nuanced view of recent events in Sweden, read this.)
In the end, I think that what this underlines is another of my personal tech policy prescriptions – we need to ensure that when technology companies are doing socially important work like influencing what news we see, they do not offload this role onto an unaccountable algorithm. Instead, they should ensure that the algorithms are overseen adequately by humans and that those humans are in turn accountable to the public for their actions.



