One of my favourite video game publishers has just announced a long-awaited revision to one of its “world simulation” games – one that covers the period from 1836 to 1936 – and the way it chose to announce and describe the game made me a little concerned. Watch the trailer (the voice-over text is in the caption)…
The whole game description except for a fraction-of-a-second glimpse of a rebellious African is focused on how that century played out in Europe and the US. There’s no sense given of how colonial success was built (to a large extent at least) on exploiting the colonized. Early in the official description of the game Martin “Wiz” Anward, the Game Director of Victoria 3 said, “Victoria 3 is not a wargame or a game about map painting” – but surely that is only true if you don’t consider what happened in the colonies. And the whole world is going to be modelled…
The way the previous game, released in 2010, handles colonization is revealing. It’s clear from this how-to-play text that players are encouraged to colonize and it explains dispassionately how best to accomplish this goal.
Colonization is the process of turning states not owned by any state into colonies. It offers several important benefits for any nation that desires to be a Great power:
Colonies are one of the most effective ways to earn prestige in the game
They provide a nation with rare trade goods and increase the abundance of other goods.
They provide fairly large populations of Soldier POPs… Later on the same page (emphasis mine)
Generally, if the player is the first to get Colonial Negotiations, and thus able to colonize, the rest of the major powers will quickly (if not immediately) follow suit due to the neighbor bonus. This causes a rush of colonization in the 1870s, especially in Africa where most empty provinces have life rating 10 or 15. (Historically, the Scramble for Africa began in 1881.) Any country who hasn’t researched Breech-Loaded Rifles by 1880 will probably miss the boat and find all of Africa already colonized.
From the Victoria 2 wiki hosted on the publisher’s site (though editable by anyone)
And as I note below, in Victoria 2 most of the un-colonised countries were labelled “primitive” and “uncivilized” in the game itself (though those labels were subsequently modified). The push-back by some fans when I raised these issues made me a little concerned, too.
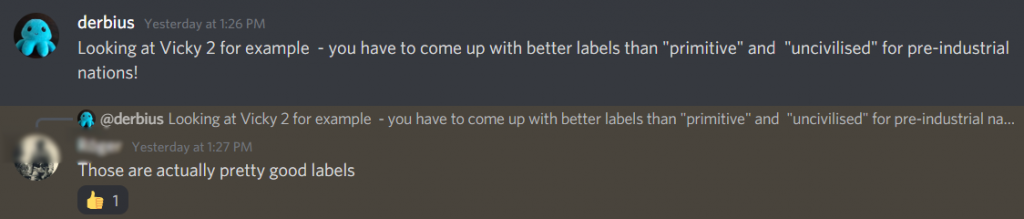
Me: There’s a huge difference between saying “we model” slavery and economic exploitation and “we make sure you recognize that your empire is built on the misery of others”
Fan 1: Every empire in history has been built on the misery of others. By that logic we can’t play any strategy game without a 30 minute introduction cinematic about modern ethics whenever we start a game… What should they know, that they don’t already? The strongest/most advanced nations engaged in large scale colonialism and some in slavery, growing in power at the cost of the countries they colonialized, as it was for thousands of years before that, just on a bigger scale. Everybody knows this. As long as Paradox follows a balanced approach in implementing it, we don’t need moral proselytizing.
Fan 2: if you don’t deal with pops living in horrible conditions then they rebel
Me: 1) “everybody” doesn’t really know about the cost of colonialism. 2) My concern is about where the focus of the game is. Saying Victoria is “just a sandbox” is an abdication of responsibility. All games draw users’ attention to some aspects of what they simulate while minimising others for the sake of game play. I’d just like to make sure the designers think about the consequences of how they design this one…
It worries me that while the game may (or may not) accurately show the negative consequences of colonization on those who were colonized, much depends on whether or how the game chooses to highlight those consequences. The earlier game treats population unhappiness as problem to be solved in order to ensure your nation/empire can continue to grow politically and/or economically, rather than setting it up as something to worry about in itself (though you can choose to focus on it if you wish).
Maybe I am sensitive to this because at 55 I am old enough that even though (because?) I went to elite schools in Canada and the UK I recall being taught essentially that the British Empire was a force for good and that Canada managed to avoid the historical moral stains of our neighbours to the south. I worry that games like Victoria 3 might perpetuate that narrative.
I don’t want to end on a negative note. One fan told me, “So far a lot of the PDXCon talk panels [where staff talk about their design decisions] have been going into the darker and brutal areas of the period, and saying that they want to portray it for how it was. So i’m not too worried about them gamifying that, or covering it up”. I haven’t been able to find those discussions though in order to hear how it’s all framed.
There’s plenty of time for them to work through these issues as they design – the game is still under development and there’s no launch schedule. But looking at the way Vicky 2 seems to have been designed and listening to the way the team has described the product as it has been unveiled seems to me a little “tone deaf”. On the other hand a Victoria 3 game that allows you to play “from the bottom up” and really get a feeling for the struggle of the colonized could be a fantastic teaching tool. And a different perspective could actually make the game more interesting, too!
Update: Delighted to see that an academic historian has also weighed in on Victoria II and how it models reality – in much more detail than I was able to do here. Well worth a read and I look forward to more from Dr Devereaux as Victoria III approaches.